
Segmentation의 기본 개념
1. Segmentation의 종류
1.1 Semantic Segmentation (의미론적 분할):

Semantic Segmentation은 픽셀 하나하나당 classification을 한다.

- 설명: 이미지 내의 각 픽셀을 특정 클래스(예: 사람, 나무, 건물 등)로 분류하는 방식입니다. 예를 들어, 이미지에 있는 모든 사람은 같은 클래스(사람)으로 분류됩니다.
- 예시: 한 이미지에서 사람, 고양이, 배경을 구분하여 각 픽셀에 해당 클래스를 할당.
Object detection과 차이점

1.2 Instance Segmentation (인스턴스 분할):
- 설명: Semantic Segmentation과 유사하지만, 같은 클래스 내에서도 각각의 객체를 구분합니다. 즉, 이미지 내의 각 객체를 개별적으로 분리합니다.
- 예시: 한 이미지에 두 명의 사람이 있다면, 각각의 사람을 별도의 객체로 구분하여 분할.
1.3 Panoptic Segmentation
- 설명: Semantic Segmentation과 Instance Segmentation을 결합한 형태입니다. 이미지 내의 모든 픽셀을 객체 또는 배경으로 분류하고, 각 객체를 개별적으로 식별합니다.
- 예시: 이미지에서 사람, 고양이, 배경 등을 구분하고, 사람마다, 고양이마다 개별적인 라벨을 부여.
2. Segmentation의 주요 방법들
2.1 Thresholding (임계값 설정):
- 간단한 Segmentation 기법으로, 이미지의 픽셀 값을 기준으로 임계값을 설정해 이를 기준으로 영역을 구분합니다.
- 주로 단순한 배경과 객체를 구분할 때 사용됩니다.
세부방법
- 단일 임계값 Thresholding: 하나의 임계값을 설정하여 이미지를 이진화합니다. 예를 들어, 임계값이 128로 설정된 경우, 0
127의 값은 검은색(배경), 128255는 흰색(전경)으로 분류됩니다. - 다중 임계값 Thresholding: 복수의 임계값을 설정하여 여러 개의 구간으로 나눕니다. 이를 통해 이미지의 여러 영역을 구분할 수 있습니다.
- 적응형 Thresholding: 이미지 전체에 동일한 임계값을 적용하지 않고, 각 픽셀의 주변 지역을 고려해 동적으로 임계값을 설정하는 방법입니다. 이는 조명이 균일하지 않은 이미지에서 효과적입니다.
- Otsu의 방법: Otsu의 방법은 임계값을 자동으로 선택하는 기법으로, 픽셀 값의 히스토그램을 분석하여 클래스 간의 분산이 최대가 되는 임계값을 찾습니다
장점:
- 계산이 매우 간단하고 빠르며, 구현이 용이합니다.
단점:
- 복잡한 이미지나 조명 조건이 다양한 이미지에서는 성능이 떨어질 수 있습니다
2.2 Edge Detection (엣지 검출) [급격한 변화를 감지]:
- 이미지에서 객체의 경계를 찾는 방법으로, Sobel, Canny 등의 엣지 검출 알고리즘을 사용합니다.
- 객체의 경계를 기반으로 영역을 분할하는데 유용합니다.
세부방법
- Sobel 필터: Sobel 필터는 이미지의 수직 및 수평 방향에서의 기울기를 계산하여 엣지를 검출합니다. 이 방법은 엣지를 강조하는 효과가 있어 경계를 잘 드러냅니다.
- Canny Edge Detector: Canny 엣지 검출기는 노이즈 제거, 강한 엣지 검출, 이중 임계값 적용, 엣지 추적의 단계를 거쳐 이미지에서 중요한 엣지만을 추출하는 정교한 방법입니다. 특히, 노이즈에 강하고, 불필요한 엣지를 제거하는 기능이 뛰어납니다.
- Laplacian of Gaussian (LoG): 이 방법은 이미지에 Gaussian 필터를 적용해 노이즈를 제거한 후 Laplacian 필터를 사용해 엣지를 검출합니다. 곡선이나 코너 부분에서의 엣지 검출에 효과적입니다.
장점:
- 객체의 경계를 명확히 추출할 수 있습니다.
단점:
- 이미지의 노이즈에 민감하며, 경계가 분명하지 않은 경우에는 제대로 된 분할이 어려울 수 있습니다.
2.3 Region-Based Segmentation:
- 비슷한 특성을 가진 픽셀을 그룹화하는 방식입니다. 대표적인 방법으로 Region Growing과 Watershed 알고리즘이 있습니다.
- 예를 들어, 비슷한 색상의 픽셀들을 모아서 객체를 구분하는 방식입니다.
세부방법
- Region Growing: 이 방법은 초기 씨앗(seed) 픽셀을 선택하고, 이와 비슷한 특성을 가진 주변 픽셀을 계속해서 병합해나가는 방식입니다. 예를 들어, 색상이 유사한 픽셀들이 서로 병합되면서 하나의 영역을 형성합니다.
- Watershed Algorithm: 이 알고리즘은 이미지의 밝기 변화를 지형의 높낮이로 간주하고, 물이 차오르는 과정을 시뮬레이션하여 영역을 구분합니다. 이 방법은 특히 객체 간의 경계를 찾는 데 유용합니다. 하지만 노이즈나 작은 지역에 민감하기 때문에, 사전 처리나 후처리가 필요할 수 있습니다.
장점:
- 이미지 내의 영역을 자연스럽게 구분할 수 있으며, 객체의 형태를 잘 유지합니다.
단점:
- 초기 조건(예: 씨앗 픽셀의 선택)에 따라 결과가 크게 달라질 수 있습니다.
2.4 Clustering-Based Segmentation:
- 이미지의 픽셀을 클러스터링(군집화)하여 분할하는 방법입니다. K-Means 클러스터링이 대표적입니다.
- 픽셀을 색상, 밝기 등 특정 특성에 따라 군집화하여 구분합니다.
세부방법
- K-Means Clustering: 가장 일반적인 클러스터링 알고리즘 중 하나로, K개의 클러스터 중심을 랜덤하게 초기화하고, 각 픽셀을 가장 가까운 클러스터 중심에 할당하는 작업을 반복하여 최종적으로 클러스터를 형성합니다. 이미지의 색상 공간에서 K개의 주요 색상을 찾아낼 수 있으며, 각 클러스터가 하나의 객체나 영역을 나타냅니다.
- Mean-Shift Clustering: 이 방법은 픽셀들이 모여 있는 밀집 영역을 찾는 데 중점을 둡니다. 각 픽셀 주변의 밀도를 계산하여 밀도가 높은 방향으로 중심을 이동시키고, 최종적으로 밀도가 높은 부분에 클러스터를 형성합니다. 이 방법은 K-Means와 달리 클러스터의 수를 미리 지정하지 않아도 됩니다.
- Gaussian Mixture Models (GMM): GMM은 픽셀 값들이 여러 개의 가우시안 분포로부터 생성된다고 가정하고, EM(Expectation-Maximization) 알고리즘을 통해 가우시안 분포의 파라미터를 추정하여 클러스터를 형성합니다.
장점:
- 이미지의 복잡한 구조를 잘 반영할 수 있으며, 다양한 객체를 구분할 수 있습니다.
단점:
- 클러스터의 수(K)를 미리 지정해야 하며, 복잡한 이미지는 제대로 분할되지 않을 수 있습니다.
2.5 Deep Learning 기반 Segmentation:
- 최근에는 Convolutional Neural Networks(CNN)를 이용한 딥러닝 모델이 Segmentation에 많이 사용됩니다. 대표적인 네트워크 구조로는 Fully Convolutional Network (FCN), U-Net, Mask R-CNN 등이 있습니다.
- 딥러닝을 이용한 방법은 복잡한 이미지에서도 높은 정확도를 자랑합니다.
세부방법
-
Fully Convolutional Networks (FCN): FCN은 전통적인 CNN의 Fully Connected Layer를 Convolutional Layer로 대체하여, 입력 이미지와 동일한 크기의 출력 맵을 생성합니다. 이를 통해 이미지의 각 픽셀을 클래스별로 분류할 수 있습니다.
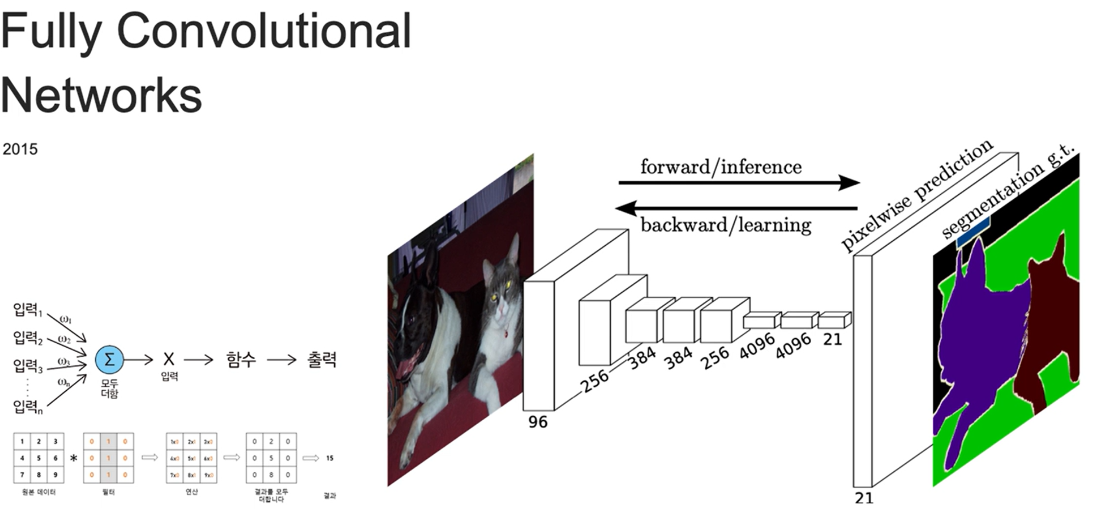
-
U-Net: U-Net은 FCN의 한 종류로, 특히 의료 영상 처리에서 많이 사용됩니다. U-Net은 인코더와 디코더 구조로 되어 있으며, 중간의 스킵 연결을 통해 고해상도 정보를 복원합니다. 이 방법은 작은 데이터셋에서도 우수한 성능을 보입니다.
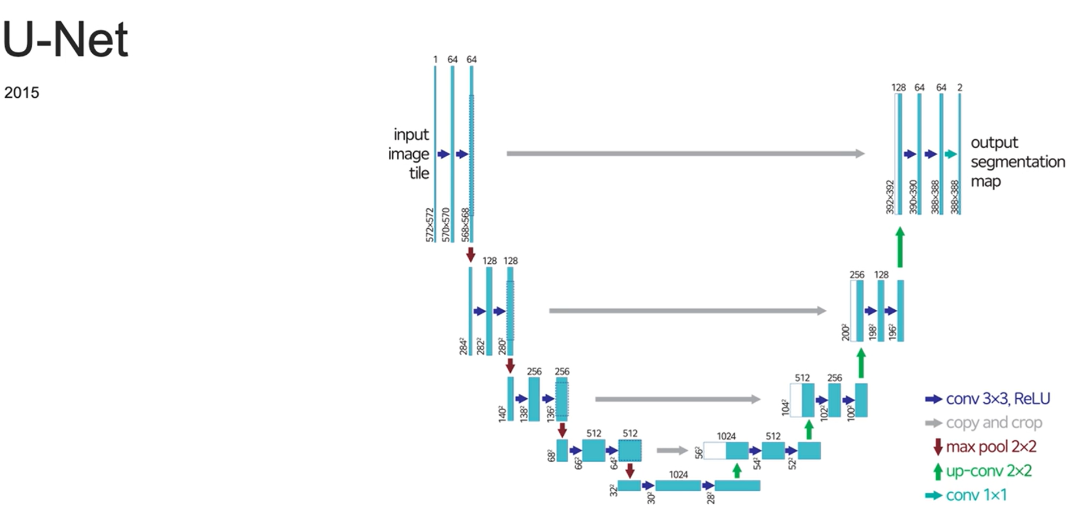
U-Net은 주로 의료 이미지 분할을 위해 개발된 딥러닝 모델입니다. 이 모델은 “U”자 모양의 네트워크 구조를 가지고 있으며, 두 가지 주요 부분으로 나뉩니다:
- 수축 경로(Contracting Path):
- 이미지에서 특징을 추출하는 부분입니다.
- 합성곱(Convolution)과 최대 풀링(Max Pooling)을 통해 이미지의 크기를 줄이며, 중요한 특징을 학습합니다.
- 확장 경로(Expanding Path):
- 수축 경로에서 얻은 특징을 이용해 이미지를 원래 크기로 복구하는 부분입니다.
- 업샘플링(Upsampling)과 스킵 연결(Skip Connections)을 사용하여 해상도를 복원하고 더 정확한 분할을 수행합니다.
포인트
- 스킵 연결: 수축 경로의 정보를 확장 경로에 전달해 더 정확한 경계 분할을 돕습니다.
- 수축 경로(Contracting Path):
-
SegNet
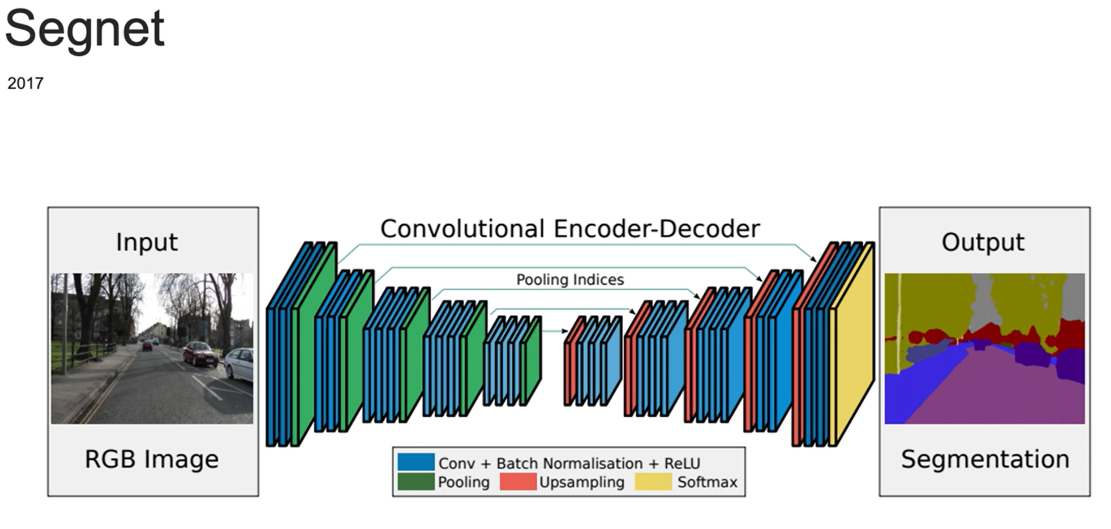
SegNet은 2015년에 케임브리지 대학에서 개발된 모델로, 주로 도로 장면과 같은 복잡한 환경에서의 세그멘테이션 작업을 목표로 합니다.
SegNet의 구조
SegNet은 엔코더-디코더(Encoder-Decoder) 구조를 따르며, 이를 통해 입력 이미지의 특징을 추출하고, 그 특징을 바탕으로 각 픽셀의 클래스를 예측하는 방식입니다.
- Encoder (인코더) 부분:
- 설명: 인코더는 주어진 입력 이미지를 점점 작은 크기로 줄여가면서 (즉, 다운샘플링) 주요 특징을 추출하는 역할을 합니다. 이 과정에서 컨볼루션 레이어와 풀링 레이어(주로 Max-Pooling)를 사용하여 이미지의 중요한 정보만 남기고, 불필요한 세부 사항을 제거합니다.
- 구조: 인코더는 일반적으로 여러 층의 컨볼루션 레이어와 Max-Pooling 레이어로 구성되며, 이는 주로 VGG16 구조에서 영감을 받았습니다.
- Decoder (디코더) 부분:
- 설명: 디코더는 인코더에서 추출된 특징 맵을 점점 복원해가며(업샘플링) 원래 이미지 크기와 동일한 크기로 되돌립니다. 이 과정에서 각 픽셀을 해당 클래스(예: 도로, 자동차, 보행자 등)로 분류합니다.
- 구조: 디코더는 인코더에서 사용된 풀링 인덱스(픽셀들이 어떻게 풀링되었는지에 대한 정보)를 사용하여 업샘플링을 수행합니다. 이 업샘플링 과정은 기존의 복잡한 연산 대신, 간단한 룩업 연산으로 풀링 인덱스를 사용하여 원래 이미지의 해상도를 복원합니다.
- Pooling Indices:
- SegNet의 주요 혁신 중 하나는 업샘플링 과정에서 “풀링 인덱스”를 사용하는 것입니다. Max-Pooling에서 각 풀링된 위치의 최대값이 어디서 왔는지에 대한 정보를 저장하고, 이를 디코더에서 사용하여 더 정확한 복원(업샘플링)을 수행합니다. 이는 일반적인 업샘플링 기법보다 메모리와 계산 자원을 절약하면서도 성능을 유지할 수 있는 방법입니다.
SegNet의 특징
- 효율적인 메모리 사용: SegNet은 풀링 인덱스를 저장하고 이를 활용함으로써 메모리 사용을 최적화했습니다. 이는 특히 메모리 제약이 있는 임베디드 시스템이나 모바일 환경에서 유리합니다.
- 높은 성능: SegNet은 도로 장면과 같은 복잡한 환경에서 픽셀 단위의 분류를 정확하게 수행할 수 있습니다. 특히, VGG16의 강력한 인코더 구조를 활용하여 이미지에서 고차원적인 특징을 잘 추출합니다.
-
활용성: SegNet은 다양한 응용 분야에서 사용될 수 있으며, 특히 자율주행 차량의 도로 장면 분석, 위성 이미지 분석, 의료 영상 처리 등에 적합합니다.
- Mask R-CNN: Mask R-CNN은 객체 탐지와 Segmentation을 동시에 수행하는 모델로, Faster R-CNN에 Segmentation 브랜치를 추가한 구조입니다. 이 모델은 각 객체의 Bounding Box와 마스크를 동시에 예측하여, 객체의 형태를 더욱 정밀하게 분할할 수 있습니다.
장점:
- 복잡한 이미지나 객체에서도 높은 정확도를 자랑하며, 다양한 응용 분야에서 활용 가능합니다.
단점:
- 많은 계산 자원이 필요하며, 모델을 학습시키기 위한 대규모의 데이터셋이 필요합니다.
3. Segmentation의 적용 사례
- 의료 영상 처리: MRI, CT 스캔 이미지에서 장기나 종양 등을 정확히 분할하여 진단에 도움을 줍니다.
- 자율 주행: 도로 상의 차선, 보행자, 차량 등을 인식하여 자율주행 시스템이 주변 환경을 이해할 수 있도록 합니다.
- 위성 이미지 분석: 지리적 지역의 구분, 예를 들어 농지, 산림, 수역 등을 분할하여 지도 제작이나 환경 모니터링에 사용됩니다.
- 증강 현실(AR): AR 앱에서 현실 세계의 객체를 인식하고 이를 기반으로 가상의 객체를 배치하거나 상호작용하는 데 사용됩니다.
댓글남기기