
#1 머신러닝과 딥러닝의 개요
1. strong AI 와 weak AI
1.1 weak AI (약 인공지능)
→ 특정영역에서 작업을 수행하는 인공지능 (자율주행 자동차나, 시리, 구글홈 등
머신러닝또한 약 인공지능에 속한다.
1.2 strong AI
-> 인간처럼 자율적이고 일반적인 지능을 가진 인공지능을 의미한다.
강한AI가 실현되려면 인간의 인지능력, 추론, 감정이해 및 자율적인 의사결정이 가능해야하며,
이 기술은 아직 실현된 예는 없다.
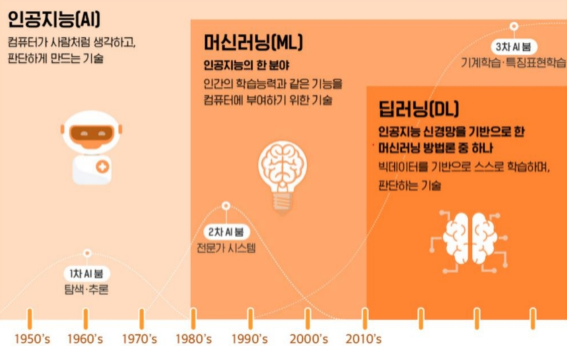
2. 머신러닝과 딥러닝의 관계
머신러닝중 인공신경망 알고리즘을 사용한것이 딥러닝.
-
인공지능: 인간처럼 해동하는 기계를 만들자! 규칙으로도 할 수 있다 (예를 들어 if문으로)
-
머신러닝: 인간이 정한 규칙이 아니라 과거의 데이터로부터 배우는 기계를 만들자
-
딥러닝: 인간의 뇌 구조로부터 영감을 얻은 모델을 이용하여 기계를 만들자
(다만 생물학적 영감은 초기 모델에만 해당된다.)
3. 머신러닝 (기계학습)
학습 또는 훈련: 데이터의 규칙을 컴퓨터가 스스로 찾아냄. 규칙을 찾아 수정하는 과정
3.1 머신러닝을 학습 방식에 따른 분류
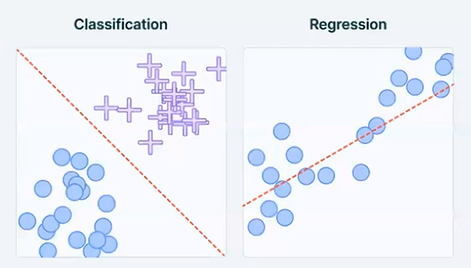
3.1.2 지도학습
지도학습은 입력과 타깃으로 모델을 훈련시킨다.
훈련 데이터 : 모델을 훈련시키기 위해 사용하는 데이터
→ 입력과 타깃으로 구성
입력: 모델이 풀어야할 일종의 문제
타깃: 모델이 맞춰야할 정답
→ 학습을 통해 만들어진 프로그램을 모델이라한다.
분류와 회귀가 대표적인 예시이다.
3.1.2 비지도 학습
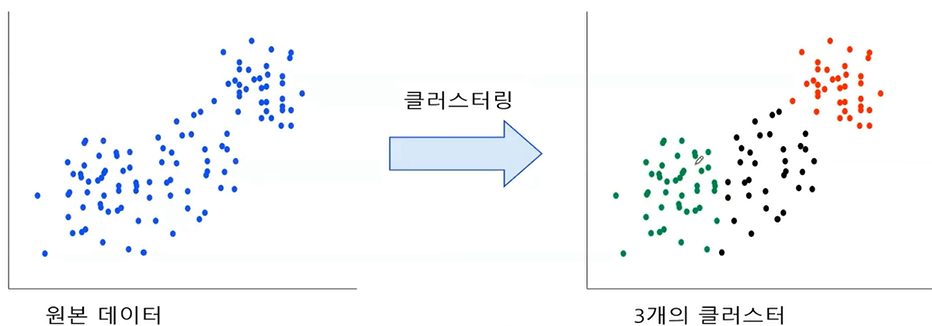
비지도 학습은 타깃이 없는 데이터를 사용한다.
대표적인 예로는 군집(clustering)이 있다.
예를 들어 모양이 비슷한것을 모아 그룹을 만드는데, 그룹에서 새로운 모양이 발견되면 새 그룹이 생긴다.
훈련데이터에 타깃이 없으므로 모델의 훈련 결과를 평가하기 어렵다는 특징이 있다.
대표적인 예시로는 클러스터링, 차원축소, 시각화 등이 있다.
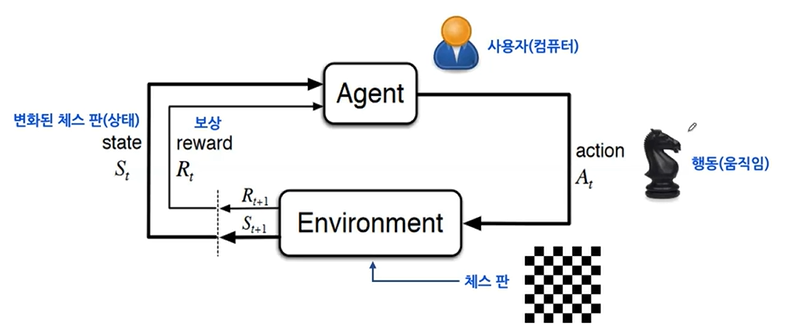
3.1.3 강화 학습
주어진 환경으로 부터 피드백을 받아 훈련한다.
머신러닝 알고리즘으로 에이전트라는것을 훈련시킨다.
훈련된 에이전트는 특정환경에 최적화된 행동을 수행 → 수행에 대한 보상과 현재상태를 받는다.
(자율주행, 자동차 알고리즘, 로봇공학등에 많이 사용된다.)
에이전트의 목표: 최대한 많은 보상을 받는것
강화학습의 대표적인 알고리즘) Q-learning, SARSA, 인공신경망을 사용한 DQN(Deep Q Network)
강화학습의 예) DeepMind
3.2 머신러닝 알고리즘 주요 구성요소 **
x는 입력: 모델이 풀어야할 문제
y는 타깃: 모델이 맞춰야할 정답
1.2는 가중치:
0.1은 절편:
(가중치와 절편을 합쳐 모델 파라미터라고 부른다.)
3.2.1 학습이란?
만약 y= ax+b일때,
데이터x 와 정답y 가 주어졌을때 정답을 분류하는 a와 b를 구하는것을 학습이라고한다.
3.3 모델과 손실함수
모델은 머신러닝의 수학적 표현이다.
즉, 훈련데이터로 학습된 머신러닝 알고리즘
모델이 예측한 값과 타깃값의 차이를 계산하는 함수를 손실함수(loss function)이라 부른다.
3.4 최적화 알고리즘으로 손실함수의 최솟값을 찾는다.
4. 딥러닝
딥러닝은 머신러닝 알고리즘중 하나인 artficial neural network으로 만든것이다.
(그 밖의 머신러닝 알고리즘에는 선형회귀나 로지스틱 회귀등이 있다.)
4.1 딥러닝과 머신러닝의 구체적인 차이점
처리하는 데이터가 다르다.
머신러닝이 처리하기 어려운 데이터를 딥러닝이 더 잘 처리한다.
딥러닝에 맞는 데이터: 이미지, 영상, 음성, 텍스트 등의 비정형 데이터 (인지에 관련한 문제를 잘 해결)
머신러닝에 맞는 데이터: 데이터베이스, 레코드 파일, 엑셀csv등에 담긴 정형데이터
5. 딥러닝을 위한 넘파이
5.1 파이썬 리스트
my_list=[10, 'hello list', 20]
print(my_list[1])
2x3 크기
| 10 | 20 | 30 |
|---|---|---|
| 40 | 50 | 60 |
my_list_2 = [[10,20,30],[40,50,60]] #3개의 요소를 가진 1차원 배열을 두개 쌓은것이다. 2x3크기
print(my_list_2[1][1]) #출력결과 50
5.2 넘파이 맛보기
파이썬 리스트로 만든 배열은 배열의 크기가 커질수록 성능이 떨어진다는 단점.
→ 이럴때 넘파이를 사용한다.
넘파이는 저수준 언어로 다차원 배열을 구현했기 때문에 배열의 크기가 커져도 높은 성능을 보장한다.
5.2.1 넘파이 설치
pip install numpy
버전확인
import numpy as np
print(np.__version__)
5.2.2 넘파이 리스트
넘파이는 파이썬의 리스트처럼 숫자와 문자열을 함께 담을 수 없다.
만약 문자 데이터가 있어도 결국 숫자로 바꿔서 입력해야한다.
import numpy as np
my_arr = np.array([[10,20,30], [40,50,60]])
print(my_arr)
[[10 20 30]
[40 50 60]]
print(type(my_arr)) #결과 <class 'numpy.ndarray'>
import numpy as np
my_arr = np.array([[10,20,30], [40,50,60]])
print(my_arr[0][2]) #결과: 30
5.2.3 넘파이 내장함수 사용
for문보다 실행속도가 매우 빠르다.
import numpy as np
my_arr = np.array([[10,20,30], [40,50,60]])
print(np.sum(my_arr)) #210
5.3 Matplotlib
파이썬 과학 생태계의 표준 그래프 패키지
5.3.1 Matplotlib설치
pip install matplotlib
5.3.2 선그래프 그리기
선그래프를 그리려면 x축의 값과 y축의 값을 맷플롯립의 plot()함수에 전달해야한다.
x축과 y축 값을 파이썬 리스트로 전달한다.
import numpy as np
import matplotlib.pyplot as plt
plt.plot([1,2,3,4,5],[1,4,9,16,25])
plt.show()
5.3.2 산점도 그리기
데이터의 x축, y축 값을 이용하여 점으로 그래프를 그린것
import numpy as np
import matplotlib.pyplot as plt
plt.scatter([1,2,3,4,5],[1,4,9,16,25])
plt.show()
random.randn()함수를 사용하여 표준 정규분포를 따르는 난수(random number)를 만든다.
import numpy as np
import matplotlib.pyplot as plt
x=np.random.randn(1000) #표준 정규분포를 따르는 난수 1000개를 만든다.
y=np.random.randn(1000) #표준 정규분포를 따르는 난수 1000개를 만든다.
plt.scatter(x,y)
plt.show()
댓글남기기